

AWS 관련 가장 큰 행사인 Summit 2024 참석 후기를 공유합니다.
5/16, 17 양일간 진행된 행사에서 가장 큰 화두는 “생성형 AI” 였습니다.
첫날은 비즈니스 트렌드와 관련된 주제였지만 세부 세션에서 LLM 을 언급한 강의들이 많았고, 둘째날은 아예 주제가 “생성형 AI 기반 기술 혁신” 이었으니 AI 가 생각보다 빠르게 여러 분야에 걸쳐 영향을 주고 있는건 사실인듯 합니다.
참석했던 세션 중 인상깊었던 주제들도 있었는데요. 기억이 희미해지기 전에 간단히 기록으로 남겨봅니다.
데이터 처리도 이제는 컨테이너로, 우아한형제들의 데이터플랫폼 혁신
우아한 형제들의 데이터 플랫폼의 상황이 얼마전 개편을 완료한 “브랜다즈 시스템 개선” 과 비슷하다는 인상을 받았다.
생성한 aws 리소스들의 시기가 다른데서 오는 비용 최적화 문제가 있었고, 불규칙한 트래픽에 대응하기에 유연한 서비스 구조가 아니었으며 많은 태스크 대비 각각의 버전이 상이해서 유지보수가 힘든 상황이었다.

우선 시도한 방법은 airflow 태스크들을 컨테이너화 하면서 eks 클러스터로 이관한 것인데 이 작업 만으로도 유지보수 비용이 꽤 많이 줄었다고 한다. 사실 너무 자연스러운 결과인데 ec2 기반으로 운영하고 있었다면 각 어플리케이션을 배포했을 당시의 버전이 시간이 지나면서 상이해졌을 것이고 당연히 버전을 쉽게 맞출수 없는 환경이었을 것이다.
이런 상황에서 airflow 태스크들을 컨테이너화만 해놔도 버전 업데이트나 작업 현행화에는 큰 이점을 가져오게 된다.
참고로 airflow 태스크의 개수가 3천개 이상이었다고 한다.
클라우드 자원 최적화와 관련해서는 eks 에서 스팟 인스턴스를 활용하고 beanpacking 을 활용해 최적화 했다고 한다. 스팟 인스턴스는 항상 유휴자원을 확보하는게 아닌 트래픽이 몰리는 현상 등으로 인해 특정 시기에 리소스가 필요한 경우 확장하는 방식인데 유휴시간 대비 피크타임 때는 9배(?) 정도의 차이가 있었다고 한다.
beanpacking 은 자원간 경합이 발생해서 어느 태스크도 실행을 할 수 없는 상황을 해결하기 위한 것인데 컨테이너 노드의 자원을 최적화해서 자원경합 문제를 최적화해서 해결해준다고 한다.
전체적으로 “이 기술이 좋다” 가 아닌 어려움을 겪던 문제와 해결해간 과정을 설명해주는 세션이어서 유익했다.
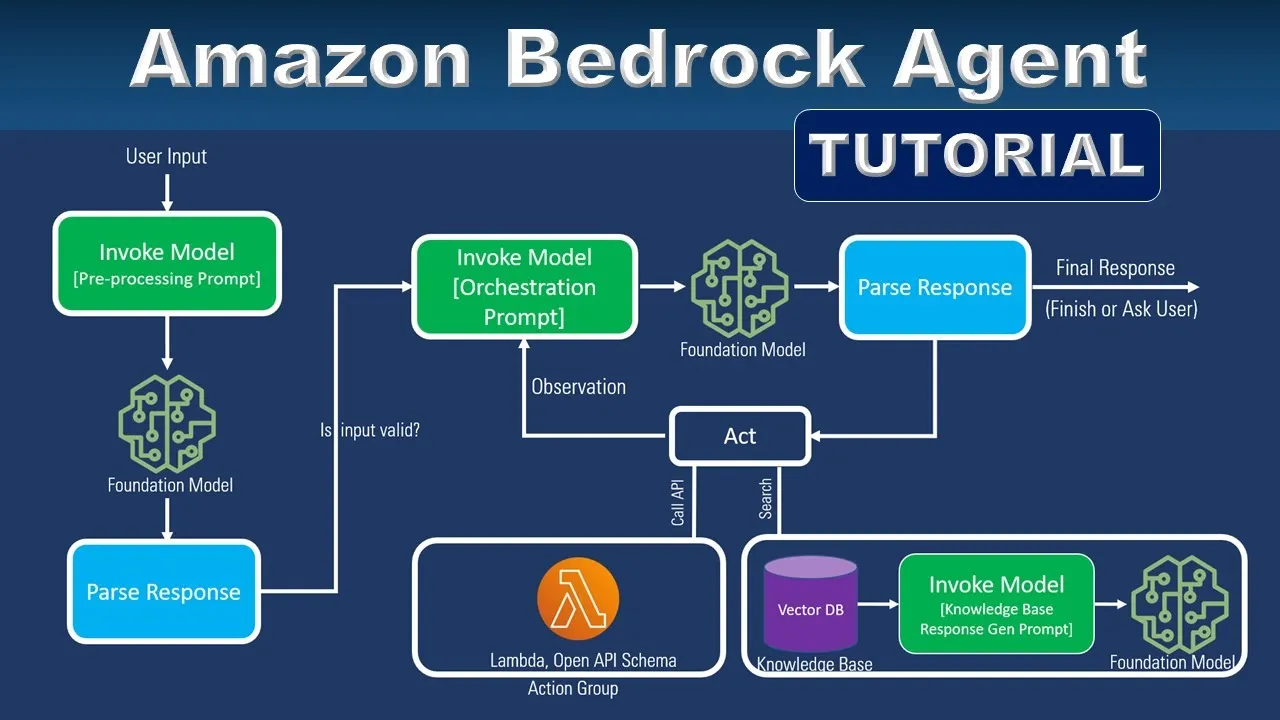
어떤 의도든 똑똑하게 이해하고 추론하는 Agents for Amazon Bedrock
최근에 가장 주목받고 있는 Gen AI에 대응하기 위해 Amazon에서 출시한 Bedrock 서비스에 대한 소개 세션으로 Bedrock으로 어떻게 기존의 Gen AI의 문제들을 해결하고 손쉽게 구축할 수 있는지를 설명해주는 세션이었다.
Amazon Bedrock은 AWS의 서비스를 이용하여 Gen AI를 구축할 수 있도록 도와주는 서비스이다.
Bedrock에서 서비스를 제공하는 LLM을 선택하고 Vector DB를 구축하고 데이터를 DB에 저장하면 누구나 손쉽게 Gen AI를 구축할 수 있다.
Gen AI 를 사용하다 보면 격게되는 여러 문제점 중 한가지인 정보의 최신화에 대한 문제를 해결하기 위해 Amazon에서 소개한 방식이 Agents for Amazon Bedrock이다.
최근에 위 문제를 해결하기 위해 가장 주목 받는 방식이 RAG 모델인데 RAG 모델은 아래 사진과 같이
Vector DB를 이용하여 Semantic Search를 통해 질문에 대한 정보를 조회하고
조회한 정보를 LLM을 통해 사람이 대답하는 듯한 형식으로 자료를 가공하는 방식으로 사용된다.
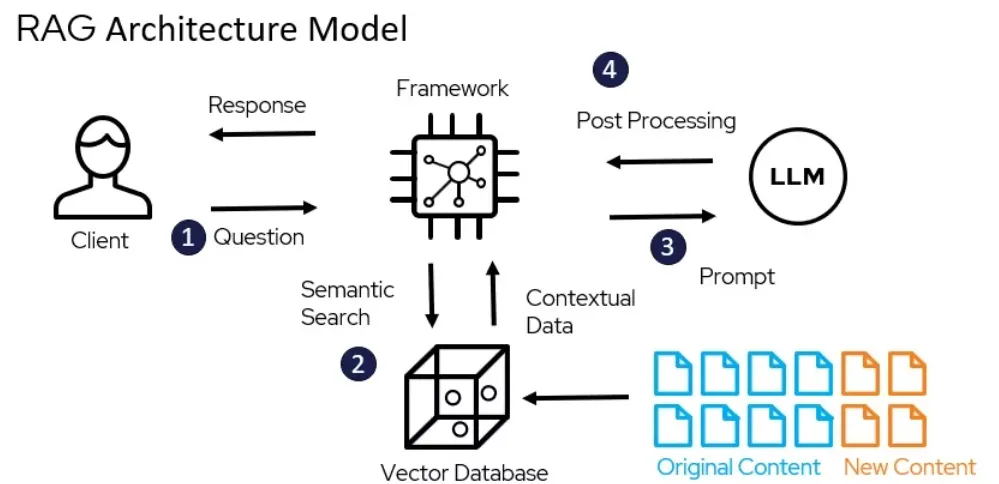
Agent for Amazon Bedrock은 Vector DB를 이용하것 뿐만 아래와 같이 Lambda를 이용한 API를 통해 실시간 데이터를 조회 할 수 있는 기능을 제공합니다.
대다수의 개발자들은 Gen AI를 만들어야 한다면 아마도 이걸 어떻게 만들어…? 라는 생각을 할 듯하다.
하지만 Amazon에서 제공하는 Bedrock을 이용할 경우 ChatGPT와 같은 검색엔진 역할을 하는 Gen AI 가 아닌 사내에서 혹은 서비스에서 사용할 간단한 AI 챗봇을 구축할 수 있을거 같다.
하이퍼커넥트의 AWS Gravition 이전을 위한 거대한 도전과 여정
AWS Gravition을 적용한 사례 및 이점에 대해서 설명하는 세션이였다.
AWS Gravition 이란 아래와 같다.

AWS Graviton은 Amazon Elastic Compute Cloud(Amazon EC2)에서 실행되는 클라우드에 최고의 가격 대비 성능을 제공하도록 설계된 프로세서 제품군입니다. 요구 사항에 가장 적합한 AWS Graviton 기반 인스턴스를 선택하세요.

위와 같이 AWS Gravition은 비용을 20% 절감 되고 전력 소모량도 60%로 절감된다.
그러하여 AWS 비용에 대해서도 절감이 가능하며, 현재는 Gravition4 4세대까지 출시하여 가격 대비 성능과 에너지 효율성을 경험할 수 있다.
하이퍼커넥트에서는 2년간 300개 이상의 인스턴스를 Gravition로 이관하였다.
현재는 RDS,Kube 등 여러가지 Managed Service는 Gravition를 사용하여 비용 절감 및 성능 효율성을 높였다.
이관의 주의사항으로는 Gravition의 경우 arm 아키텍처를 사용하기에 서비스에서 사용하는 라이브러리의 이미지가 arm 아키텍처를 호환하는지 확인이 필요하며 호환되지 않을 경우 요청하거나 출시를 기다려야 한다. 마이그레이션 시 가장 난이도가 높은건 파이썬 이라고 한다. 언어 특성상 c 언어로 작성된 모듈을 사용하는 경우가 빈번하고 아키텍쳐 변경에 따른 사이드 이펙트가 크기 때문이라고 한다. Go 언어는 난이도 “하”, Jvm 환경의 언어는 “중” 정도라고 하니 공비서와 브랜다즈의 서비스들은 큰 이슈는 없을듯했다.
이번 세션으로 보았을 때 저희가 사용하고 있는 Gravition2 t4g 인스턴스 처럼 적극적으로 활용할 수 있도록 서비스를 분석하고 정리 이후 그에 맞는 범용, 컴퓨팅 최적화, 메모리 최적화 등등.. 그의 맞는 Gravition 인스턴스를 사용하면 더욱 비용 최적화에 효율적으로 사용 가능하다고 느꼈습니다.
플랫폼 엔지니어링 기반 개발자 생산성 극대화
이번 세션에서는 카카오페이증권 데브옵스 김성민 데브옵스 엔지니어, 당근 김승호 소프트웨어 엔지니어 두분이 사내에서 진행한 플랫폼 엔지니어링을 소개하며 진행하였다.
플랫폼 엔지니어링은 개발자들은 어플리케이션 개발에 집중 할 수 있도록 배포 및 모니터링 등 복잡성을 줄이고 효율적으로 할 수 있도록 플랫폼을 제공하는 것 이다.
카카오페이증권의 경우 적은 인원으로 여러 개발자의 많은 요청을 처리하기에 많은 리소스가 들어 문제의 근본과 가이드 문서화 하고 자동화에 집중하기 시작하였다.
CI/CD 플랫폼인 Wallga, Kubernetes Event 플랫폼인 Hawk Eye, kubectl 사용성 개선 플랫폼 Hela 등등을 활용하여 WECAN 이라는 공유 플랫폼을 생성하여 사내에서 개발자가 보다 편하고 효율성을 높일 수 있도록 하였다.
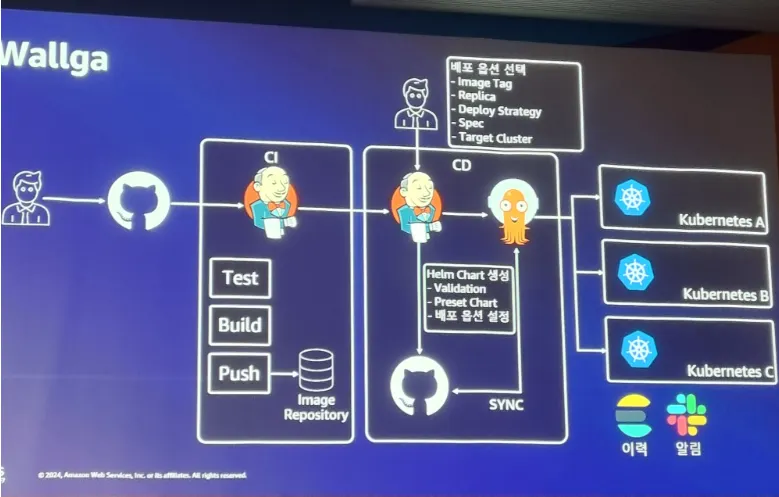
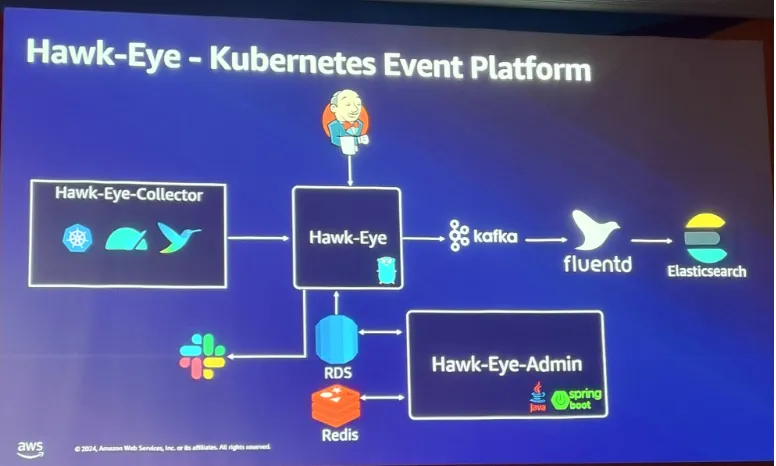
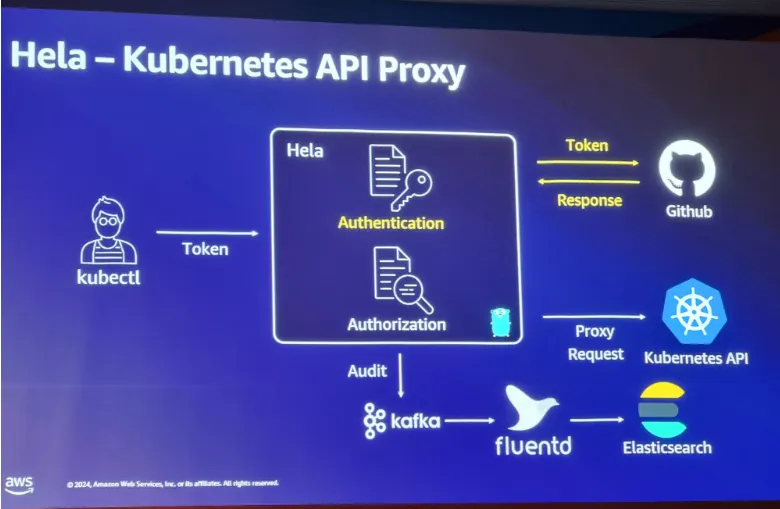
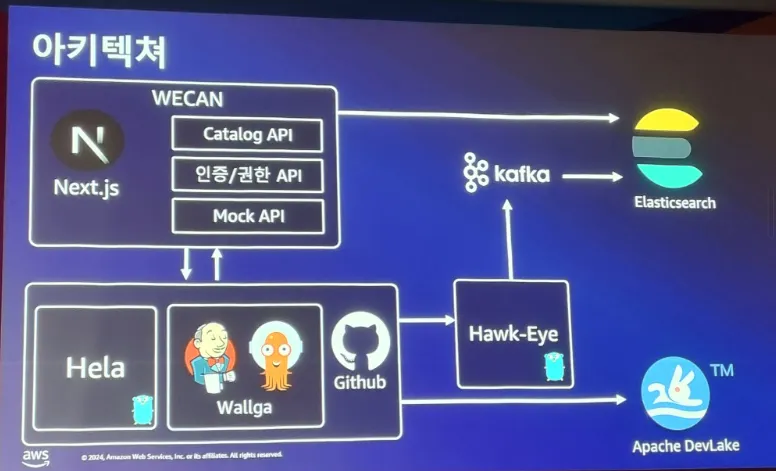
아직까지는 부족함이 있지만 플랫폼화 하여 개발자분들이 불편함 없이 사용 수 있도록 하는게 목표라고 하였다.
이번엔 당근 세션의 경우
개발자가 AWS 관리에 자유롭게 관여할 수 있는 구조로 되어있다. 그러다 보니 클라우드 담당자 리소스에 부하가 생겨 코드 베이스로 관리 가능한 IaC를 도입하게 되었지만 자유롭게 콘솔에서 작업을 하다보니 IaC 싱크가 맞지 않아 IaC를 걷어내었다.
그러하여 카카오페이증권의 WECAN 이라는 플랫폼 처럼 당근에는 KRP(캐럿 리소스 플랫폼)을 만들어 제공하였다.
KRP(캐럿 리소스 플랫폼) 경우 AWS API(boto3)를 내부 어드민화한 것으로 보여지고, 기능이 추가될 때마다 개선이 필요하고 직접 AWS API를 사용하기에 콘솔에서 자동처리되던 기능(관련 리소스 자동 삭제)을 직접 핸들링해야하는 이슈도 발생하였다.
사용자 경험의 중요성을 느꼈고, 개발팀의 요청이 많이 줄었다고 함.
플랫폼 엔지니어링을 통해 플랫폼화 하여 개발자는 개발에만 전념하도록 경계를 두고 생산성을 높일 수 있는 장점에 대해서 고민하면 이렇게 내부적으로 플랫폼화 할 수 있구나 라는 점을 느꼈으며, 시간을 투자하여 CI/CD 및 인스턴스 관리 측면만 구성해두면 보다 더 어플리케이션 개발에 생산성을 늘게 할 수 있고 인스턴스 관리도 명확하게 할 수 있을 것 같다는 생각이 드는 세션이였습니다.
IPv6 활용 전략
IPv6 활용 강의는 조금 어려운 내용들이 많았다. aws vpc 만을 다루는게 아닌 IDC 환경과의 통신도 다루고 있었고 eks 등 사용해보지 않은 서비스들에 대한 내용들도 섞여 있었다.
두분이 강연을 진행했는데 앞부분은 하이브리드 네트워크 환경에서의 비용 최적화된 통신환경 구축이었고 두번째는 IPv4 에서 IPv6 로 전환해가며 겪었던 시행착오에 대한 강연이었다.
첫번째는 aws vpc 와 IDC 간에 발생할 수 있는, 또는 서로 다른 계정간의 vpc 에서 발생하는 네트워크 통신 등 다양한 상황에 대해 어떻게 구성을 해야 ip 중복 등의 이슈와 비용 문제를 최소화 할 수 있는지 다루고 있었는데 발표자분이 재직중인 회사가 SKT 라는 거대 네트워크를 다루는 환경이었기에 만나게 되었던 문제 상황으로 보였다.
공통되는 문제 해결방법이 있었는데 IPv4 환경에서 private ip 가 겹치는 등의 상황에서는 별도 vpc 의 subnet 을 통해 통신하게 하는 식으로 ip 중복을 피하는 것이었다. 우리도 브랜다즈와 공비서 aws 계정이 분리되어 있고 vpc 의 네트워크 대역대 설계를 잘 한다고 해서 중복이 아예 없을수는 없어서 추후 활용할수 있겠다는 생각을 했다.
IPv6 로의 전환 강연은 결론부터 이야기하면 전환에 실패했다고 한다.
IPv6 를 고려하게된 이유가 라우팅 테이블 관리를 간소화하기 위함이었다고 하는데 IPv4, IPv6 의 가장 큰 차이가 private network 개념이 있고 없고의 차이, 두 프로토콜간 통신이 불가능한 부분이 있다보니 이를 해결하기 위해 듀얼스택으로 네트워크 구성을 한다던가 하면서 라우팅 테이블이 2배로 늘어나는 상황이 만들어졌다고 한다.
여기에 원인이 된것은 aws 리소스 중 IPv6 를 지원하지 않는 것들이 있어서라고..
결론을 알고나니 조금 허무해지기도 하는 강연 내용이었지만 그 과정에서 고민하고 풀어내려고 했던 방법들을 통해 언젠가는 대응하게 될 IPv6 에 대한 지식이 조금은 생기게 되었다.
Amazon Bedrock을 활용한 프롬프트 엔지니어링 모범사례
프롬프트 엔지니어링 세션의 내용중 일부는 실무에서 Gen AI를 사용할 경우에도 활용하면 좋을 듯한 내용들이 많은 세션이었다.
프롬프트 엔지니어링의 기법중 한가지를 예시로 강연자가 질문한 내용을 같이 생각해보자.
10 더하기 10은 무엇일까요?
Plain Text
복사
위 질문에 대한 대답을 생각해보면 당연히 20 이라는 대답이 나올것이다.
그렇다면 아래 질문에 대한 내용을 다시 생각해보자.
<예시>
1 더하기 1은 덧셈 문제이다.
1 빼기 1은 뺄셈 문제이다.
1 곱하기 1은 곱셈 문제이다.
1 나누기 1은 나누기 문제이다.
<질문>
그렇다면 10 더하기 10은 무엇일까요?
Plain Text
복사
위와 같이 질문을 하게 되면 처음 질문과 완전히 다른 질문이 되버린다.
이렇게 질문에 대한 컨텍스트가 제공하게 되면 Gen AI는 컨텍스트를 기반으로 편향된 대답을 하게 된다.
이런 기법을 이용하면 우리가 원하는 방향으로 구체화된 답변을 출력시킬 수 있다.
다음 예시는 페르소나를 사용한 방식이다.
<페르소나>
물리학자
<질문>
양자 얽힘에 대해 설명해줘
Plain Text
복사
위와 같이 질문을 한다면 “2개 이상의 입자가 상호 작용을 해서 서로 연관된 현상” 과 같이 전문적인 대답을 할것이다.
아래와 같이 질문을 한다면 어떻게 될까?
<페르소나>
3살 어린아이
<질문>
양자 얽힘에 대해 설명해줘
Plain Text
복사
위와 같이 질문을 하면 Gen AI는 무엇인지 모른다고 대답하거나 장난스러운 대답을 할 것이다.
위와 같이 질문을 할 때 페르소나, 예시 와 같은 추가적인 정보를 제공할 경우 우리가 원하는 답변을 더 정확하게 얻을 수 있다.
그 다음 예시를 봐보자.
일반적인 프롬프트 상황인 아래의 예시를 봐보자.
Q: 로저는 5개의 테니스 공을 가지고 있다.
그는 테니스공 2캔을 살 수 있고 각 캔에는 3개의 테니스 공이 담겨져 있다.
몇개의 테니스 공을 가지고 있는가?
A: 11개 입니다.
Q: 식당에 23개의 사과가 있다. 점심 시간에 20개를 사용하고 6개를 추가로 구입하였다.
몇개의 사과를 가지고 있는가?
A: 27 개 입니다.
Plain Text
복사
어떤 계산인지 모르겠지만 Gen AI는 틀린 대답을 하게 된다.
이런 오류를 개선하기 위해 사용하는 방식이 사고 사슬 프롬프팅이다.
아래는 사고 사슬 프롬프팅을 한 예시이다.
Q: 로저는 5개의 테니스 공을 가지고 있다.
그는 테니스공 2캔을 살 수 있고 각 캔에는 3개의 테니스 공이 담겨져 있다.
몇개의 테니스 공을 가지고 있는가?
A: 로저는 5개의 공으로 시작하였다. 3개의 공이 담긴 테니스 공 캔 2개를 구입하여 6개가 추가되어
5+6 = 11. 정답은 11입니다.
Q: Q: 식당에 23개의 사과가 있다. 점심 시간에 20개를 사용하고 6개를 추가로 구입하였다.
몇개의 사과를 가지고 있는가?
A: 식당에는 23개의 사과를 가지고 있었습니다. 그리고 그들은 20개를 점심에 사용하였으니
23 - 20 = 3. 그리고 그들은 6개의 사과를 구매하였습니다.
그래서 3 + 6 = 9. 정답은 9입니다.
Plain Text
복사
사고 사슬 프롬프팅이 적용될 경우 Gen AI는 산출 과정을 포함 시켜 어떻게 결과를 산출하는지 확인 할 수 있다.
위 예시 처럼 프롬프트 기법에 따라 Gen AI의 대답은 달라진다.
세션에서는 Gen AI를 만들어 나아갈 때 정확한 답변을 얻기 위한 고급 프롬프팅 기법 11가지에 대해 설명하였다.
고급 프롬프팅 기술을 모두 적용하면 당연히 보다 높은 정확도의 대답을 얻을 수 있을것이다.
하지만 AWS SA는 모든 구성 요소를 활용하여 가장 근접한 결과를 만드는 방식을 권장하지 않았다.
왜냐하면 이 모든것은 토큰을 사용하고 토큰은 즉 돈으로 연결되기 때문이다.
프롬프팅 엔지니어링은 이론적으로 증명된 기법이 아닌 경험적 검증을 바탕으로 하고 있다.
소프트웨어 개발론 중 TDD와 같이 테스트 케이스를 정의하고 작성된 프롬프트를 검증하여 어떤 부분이 잘됐고
어떤 부분이 모자랐는지 판단하면서 반복을 수정하는 것이 더 효율적이고 좋은 결과를 만들어 낼 수 있다.