
터너
Vector Search 후기
Vector Search 란 머신 러닝을 활용하여 텍스트, 이미지 등 비정형 데이터의 의미와 컨텍스트를 숫자 표현으로 변환합니다.
Vector Search 는 알고리즘을 통해 가장 유사한 데이터를 검색해 주는 기능입니다.


•
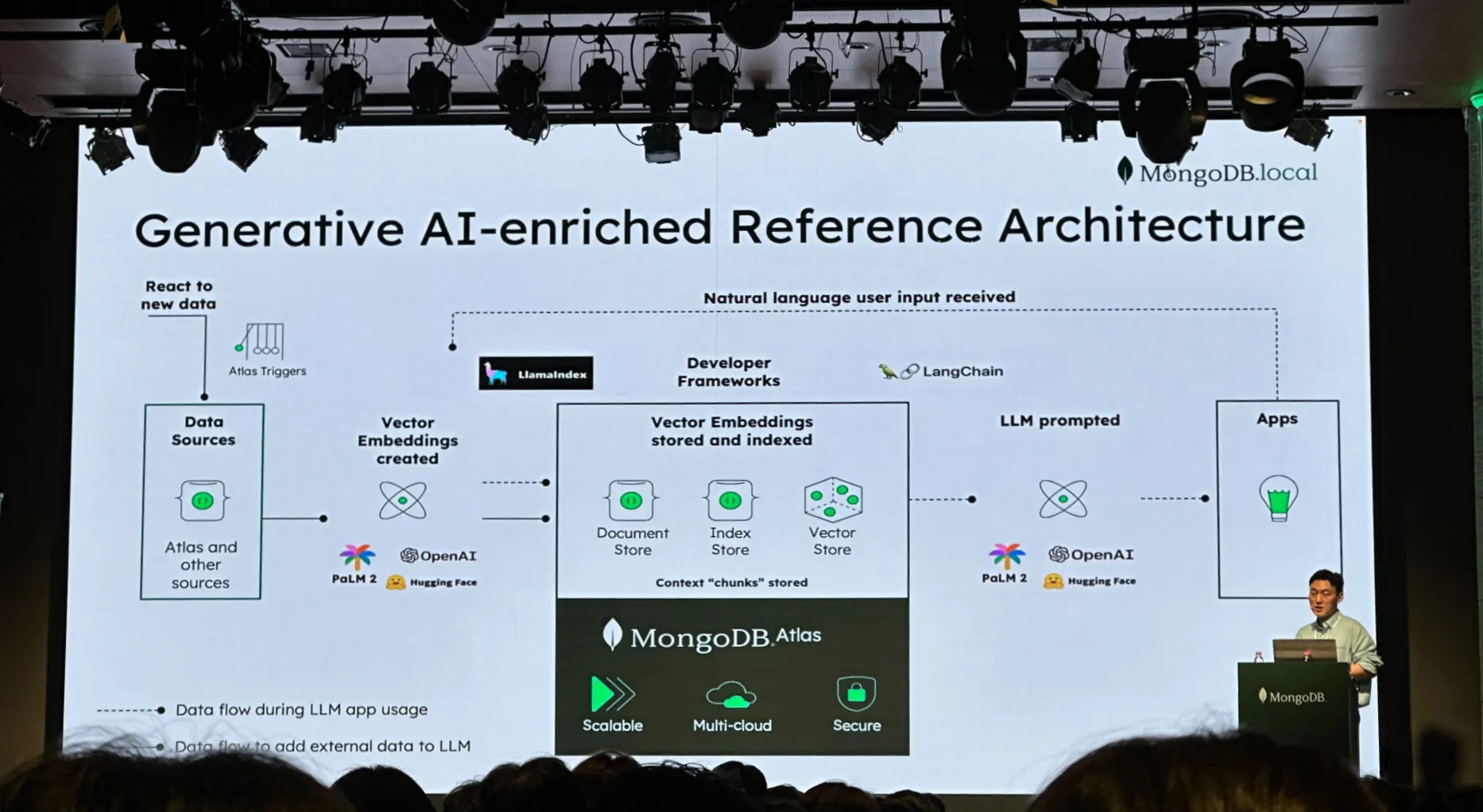
Atlas에서는 Vector Search 기능을 통해 Semantic Search와 Generative AI 개발에 어떻게 응용하는지를 제시하였습니다.
•
Atlas에서는 머신 러닝 알고리즘을 통해 반환된 숫자 값을 저장하고 저장한 값을 기반으로 유사도 검색을 지원합니다.

•
이러한 유사도 검색을 활용하여 아래와 같은 기능들을 간단한 코드로 구현할 수 있습니다.
◦
유사 텍스트 검색 → ex) 검색창에 과일을 검색하면 사과, 포도, 배와 같은 항목들이 나열된다.
◦
이미지 검색 → ex) 일론 머스크 사진을 통해 이미지 검색을 하면 일론 머스크의 사진이 제일 상단에 리스트업 된다.
◦
GPT → 보험 약관 PDF 문서를 학습 시킨 LLM 모델에게 특정 상황에 대한 내용을 문의하면 정리하여 응답해주고 번역도 가능하다.
•
아래 링크는 Atlas와 Python를 활용하여 Hugging face에 있는 오픈소스 ML 알고리즘을 통해서 간단하게 Semantic Search를 구현하는 것을 보여줍니다!

Event Pipeline
•
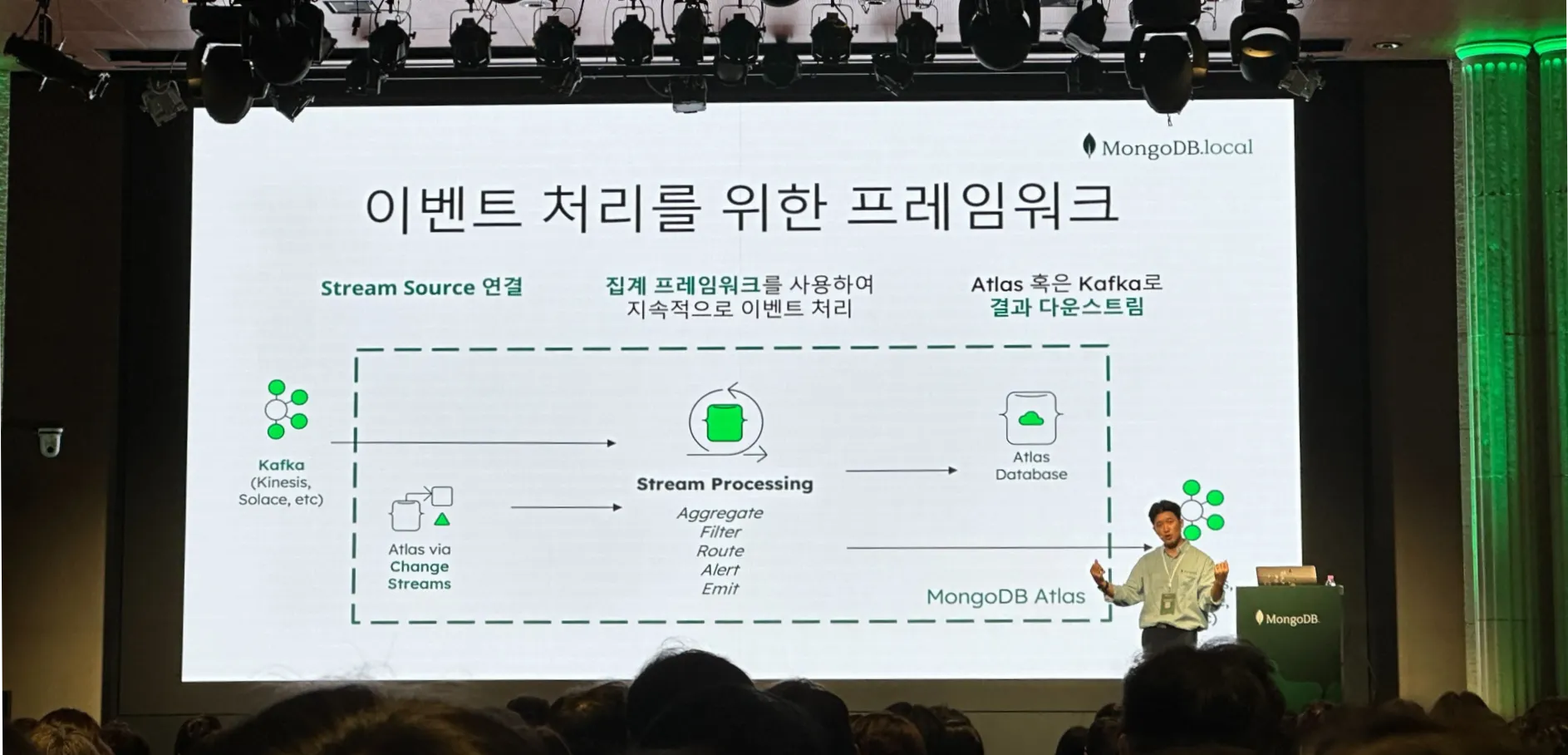
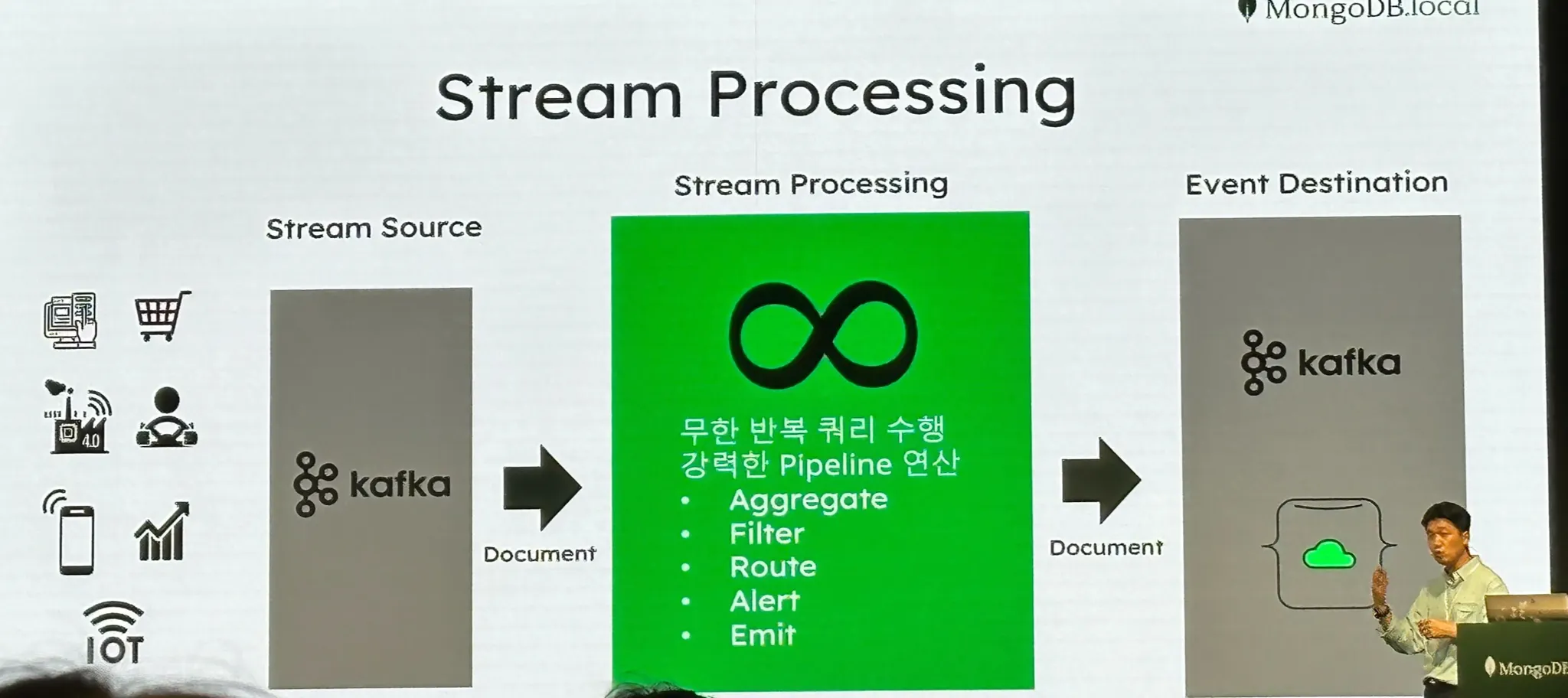
Atlas에서는 Kafka Connector를 이용하여 데이터 전처리 혹은 후처리를 지원합니다.
◦
이 과정을 보통 다른 오픈소스에서 수행하는데 Mongo 에서 대체할 수 있다.
•
Atlas의 Pipeline을 정의하고 가공된 데이터를 Atlas에 저장하거나 다른 Kafka Event로 데이터를 보내줄 있다.
니키
참석 계기 : MongoDB를 비롯한 NoSQL을 사용해보고 싶었는데 어떤 상황에 도입해볼 수 있을지 인사이트를 얻기 위해 참석하게 되었다.
발표 내용 : 정말로 그런지는(?) 아직 사용경험이 없어서 알 수 없지만 MongoDB는 RDS를 완전히 대체하거나 그 이상의 역할을 할 수 있다는 내용이 있었다. MongoDB 쪽 아키텍트들이나 AWS, GCP 아키텍트들이 발표한 내용으로는 크게 MongoDB Atlas로 마이그레이션을 쉽고 간단하게 할 수 있는 기능을 제공하고 있으며 이를 위한 기술적 지원도 잘 이루어져 있다는 것이었다. 전문 DBA가 없거나 기술적 지원 혹은 클라우드가 제공하는 다양한 서비스와의 연계를 계획하고 있다면 Atlas를 사용하는 것도 좋은 선택일 것 같았다. 또한 다국적 서비스를 제공하고 있거나 IoT 서비스를 제공하는 기업의 경우에는 수많은 데이터가 발생하기 때문에 Atlas로 전환했을 때 클러스터 운영이나 샤딩같은 수평적 확장에 유리하다는 사례를 발표했다. 또한 Vector Search 같은 기능을 통해 비즈니스 인사이트를 도출하는데도 도움을 줄 수 있다.
Relational Migrator
SQL 워크로드를 MongoDB 워크로드로 가장 빠르고 안정적으로 전환시켜 주는 도구
MongoDB를 왜 사용해야 하는가?
1.
엄청난 데이터의 증가 속도
•
그러나 SQL은 조인을 기반으로 한 데이터베이스이기 때문에 시간 복잡도를 머지 조인이라고 가정해도 O(NlogN)이다.
•
반면 Lucene과 같은 경우에는 O(logN)의 시간복잡도를 가지고 있다.
•
따라서 SQL을 현대 어플리케이션에서 사용하기 위해서는 성능을 포기하던가 하드웨어 스펙을 보완해야 한다.
2.
사업 환경의 변화
•
현대 비즈니스 환경은 계속 끊임없이 아주 빠르게 발전하는 변화를 하기 때문에 데이터베이스 어플리케이션 또한 유연한 스키마에 대응해야 한다.
•
개발 프로세스 시간
◦
SQL을 사용하면 정규화 → 모델링에 걸리는 시간으로 전체적인 개발 기간이 늘어남.
◦
반면 NoSQL을 사용하면 애플리케이션이 사용할 오브젝트를 먼저 결정하고 그대로 스토리지에 저장되기 때문에 전체 개발 프로세스가 단축된다.
•
MSA
◦
마이크로서비스마다 다른 데이터베이스를 사용한다는 것은 결국 Query Language가 달라진다는 것이다. 따라서 이에 대한 학습 시간도 무시할 수 없게 된다. 그러나 MongoDB를 사용하면 데이터베이스는 MongoDB를 선택하고 서로 다른 데이터 모델을 사용하게 되기 때문에 하나의 통일된 Query Language Interface를 사용할 수 있게 딘다.
결국 Relational Migrator란 무엇인가?
•
SQL 디자인을 MongoDB 디자인으로 전환할 수 있고, 그 디자인을 바탕으로 데이터를 카피해준다. 또한 어플리케이션에도 새로운 코드가 필요할 수 있는데 거기에 대한 Code Generation도 해주고 있다. 또한 GUI로 프리뷰를 보여주는 기능도 제공하고 있다.
•
두가지 마이그레이션 옵션이 존재
◦
SnapShot Migration Option
◦
Continous Migration Option
벤티
Samsung Knox 클라우드 솔루션의 mongoDB 활용 사례
1.
삼성 Know 사용하는 MongoDB 환경
MongoDB
Installed on EC2 instance
Memory optimized type instance
Replica set (P/S/S)
Version : v4.4
(Enterprise Advanced)
Cluster : 15+
DB: 65+
Collections : 950+
Data size : 4TB+
Largest Collection : ~1TB, 51 indexes
Ops manager
Version : v5.0.21
Monitoring - Real Time, Trend
Alert
Backup
Maintenance
Index manage
Account manage
실제 운영하면서 발생한 이슈
•
Index Creation
실제 인스턴스에 설치 된 MongoDB와 Replicaset을 이용할때
2개의 Index 생성 할 경우
Primary Node는 첫번째 인덱스가 수행이 되고 2번째 index 생성이 될때 Secondary Node 에서 첫번째 인덱스 생성이 진행 중이여서 인덱스 생성이 지연되는 문제가 발생 하여 Secondary Node가 읽기로 사용될 경우 Index가 적용되지 않는 문제가 발생함
◦
해결방법
▪
Confirm the index creation on Secondary node [mongodb.log - Index build Done]
▪
Avoid the peak time
•
Read tickets become to 0
sorting 수행 시 지연으로 인한 ticket이 0이되는 현상
◦
해결 방법
▪
Quick workaround: Drop the long running quries
▪
Re-define the requests - read preference : primary or secondary preferred
▪
Apply the timeout option for read queries

•
Write tickets become to 0
◦
많은양의 FindAndModify queries가 거대한 Collection (huge collection)에 전달 될 경우 발생
◦
mongoDB version은 4.2
◦
해결 방법
▪
Quick workaround: Drop the unexpected index
▪
Create the proper index with “Equal-Soring-Range” rule.
▪
Use hint properly
Schema Versioning
추가 요구사항에 따라 Application에서 버전 분기가 필요할때
아래와 같이 만들어주면 Application에서 분기하기 쉬워짐 (MongoDB의 Schma 유연성 이용)

as is
{
"_id" : ObjectId("54f2esfe3gdaerfew2552fdfwr2efe3f3"),
"deviceId": "d00012345",
"imeI" : "a12345678a"
}
JSON
복사
to be
{
"_id" : ObjectId("54f2esfe3gdaerfew2552fdfwr2efe3f3"),
"deviceId": "d00012345",
"imeI" : "a12345678a",
"secondimei" : "b123456789b",
"schema_version": "2",
...
}
JSON
복사
장점
•
다운타임 없이 우아하게 마이그레이션 할 수 있다
•
제어 없이 빠른 마이그레이션
후기
삼성 knox에서 실제 운영하면서 발생한 이슈공유를 통해 미리 장애가 될만한 포인트들을 알 수 있었다.
Replicaset 구성시 Index 생성에 Primary와 Secondary의 생성 시점 차이가 있을 수 있고, 큰 Collection을 사용할 경우 index hint를 통해 index를 확실히 사용하도록 강제해야 장애를 막을 수 있을것 같다.
MongoDB의 장점을 사용하여 Versioning을 직접 추가하여 downtime없이 자주 변경되는 비지니스를 downtime 없이 migration 하는 방법도 알 수 있었다.