

들어가며
안녕하세요. 공비서팀 백엔드 개발자 레이입니다. 작년 10월 즈음 공비서팀 백엔드, 프론트 인프라 구조를 개선하였습니다. 이 후 간헐적으로 웹 서비스로 이동이 안되는 장애가 발생하였는데요. 원인을 찾기 어려웠던 장애였어서 해결하는 과정들을 기록하면 좋을 것 같아 포스팅 합니다.
배경
JSP와 Next.js(React)의 공존
공비서는 기존에 JSP로 웹 서비스를 제공하다가 Next.js로 분리 및 개선하는 과정에 있습니다.
개선 중이라 일부 페이지들은 Next.js, 일부는 JSP로 제공되고 있습니다.
백엔드 애플리케이션은 AWS ElasticBeanstalk(이하 EB)을 사용하고 있는데요, JSP와 Next.js를 동시에 제공하기 위해 EB의 Proxy Web Server에서 URL 패턴 기반으로 프록시 설정을 하여 JSP와 Next.js가 함께 동작하도록 처리하고 있습니다.
예를 들면 다음과 같은 설정이 있는데요.
ProxyPassMatch ^/mobile-verification(.*)$ https://${CRM_FRONT_SERVER_DOMAIN}/mobile-verification$1
ProxyPassReverse /mobile-verification https://${CRM_FRONT_SERVER_DOMAIN}/mobile-verification
Plain Text
복사
공비서 도메인으로 https://gongbiz.kr/mobile-verification 요청이 오면, 이 설정에 의해 프론트 도메인으로 프록시 됩니다.
프론트와 백엔드 인프라 개선
프론트
Next.js 프론트 애플리케이션도 기존에는 EB를 사용하여 구축되었었습니다. 그러나 EB의 오토스케일링 과정에서 nginx chunk가 맞지 않아서 발생하는 장애, 스왑 배포의 어려움 등 여러 이슈가 있었습니다. 이를 개선하기 위해 AWS ECS Fargate 방식으로 프론트 인프라를 변경하는 작업을 진행했습니다.
백엔드
공비서 고객들에게 빠르게 가치를 전달하기 위해서는 개발자의 생산성을 높였어야 했는데요. 프레임워크나 언어에서 지원하는 여러 기능들을 활용할 수 있었고, 프레임워크와 언어 버전에 따라 관련된 Gradle 빌드 툴, 라이브러리 호환성 등에서 생기는 이슈를 해결하기 위해 스프링부트를 2.1에서 2.7로 JDK를 8에서 17로 업그레이드 했습니다. 또, 백엔드의 여러 애플리케이션들이 각각 레포지토리로 분리되어있었는데요. 이를 모노레포, 멀티모듈을 적용하여 하나의 레포에서 관리하도록 구성했습니다. 이 방식을 통해 흩어져 있는 코드를 하나로 관리할 수 있게 되었고, 중복 코드를 개선하고 Enum 등의 타입이 불일치하여 발생하는 버그를 해결하여 생산성을 높이고 안정성을 높일 수 있는 기반을 마련하였습니다.
모노레포/멀티모듈, 언어의 변경으로 CI/CD 구성을 변경하고 인프라 또한 Tomcat 8 기반에서 Java Platform 기반으로 변경하였습니다. 당시의 EB에서 지원하는 Tomcat 플랫폼은 JDK 17을 지원하지 않아서 Java Platform을 선택했습니다. 당시에는 Tomcat 10만 JDK 17을 지원했고, 그 외에는 Tomcat 8에 JDK 8과 11 버전이 있었는데요. Tomcat 10은 JakartaEE 여서 코드 변경도 필요했기 때문에 선택지에서 제외되었습니다. Java Platform은 프록시 서버로 Nginx만 지원하여서 기존에 사용하는 Apache Proxy Server를 Nginx로 변경하게 되었습니다.
장애 발단 
백엔드와 프론트 인프라를 개선하면서 이슈 없이 배포하고 서비스를 운영하면서 고객들에게 안정적인 서비스를 제공함과 동시에 개발자들이 배포 걱정 없이 작업을 할 수 있다고 기대했습니다.
인프라 개선 직후에는 이런 기대가 충족되면서 좋았습니다. 배포도 걱정 없이 할 수 있게 되었고요. 그런데 갑자기 웹에서 502 또는 504 에러가 발생하게 되었습니다.

이후 간헐적으로 해당 이슈가 발생하게 되면서 고객들에게 안정적인 서비스를 제공하지 못 하게 되었습니다.
공비서 서비스는 뷰티샵 원장님들의 샵 운영을 도와드리는 서비스인데요. 장애가 발생해서 서비스를 이용 못 하면 직접적인 매장 운영과 매출에 영향을 끼치게 되어 안정적인 서비스 제공이 그 무엇보다 중요합니다.
그런데 같은 유형의 장애가 간헐적으로 발생하게 되었는데, 매번 원인 파악을 하고 조치를 해봐도 해결이 안 되었습니다.

간헐적인 502/504 장애보고서
1차 조치
프론트 ECS의 ALB에 설정된 Deregistration delay 설정을 기본값 300초에서 900초로 연장 해봤습니다.
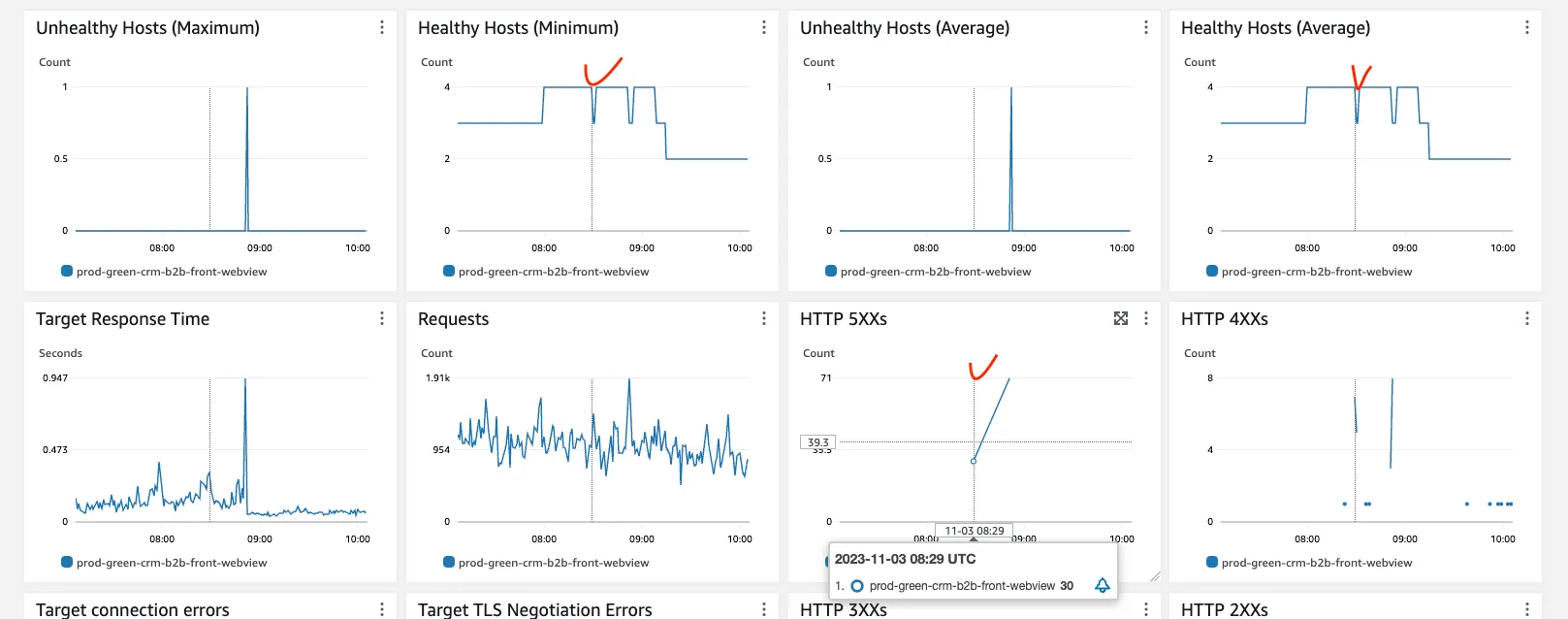
스케일 인(확장된 인스턴스가 죽는 상황) 상황에서 에러가 발생하는 모니터링
로드밸런서와 ECS 컨테이너 모니터링 지표를 보니 스케일아웃되어있는 상황에서 스케일인 되면서 인스턴스가 갯수가 줄어드는 시점에 에러가 발생한 것으로 보였습니다. Deregistration delay는 죽기로한 인스턴스(드레이닝)에서 이미 요청 들어온(in-flight request)를 처리하는데 기다리는 시간입니다. 최대한 이미 들어온 요청을 처리하고 죽도록 해야하는데 5분보다 더 길게 설정을 해봤습니다. 이를 통해 스케일인 상황에서 내려가는 인스턴스에서 요청을 잘 처리하고 내려가서 장애가 해소되길 기대했습니다.
2차 조치
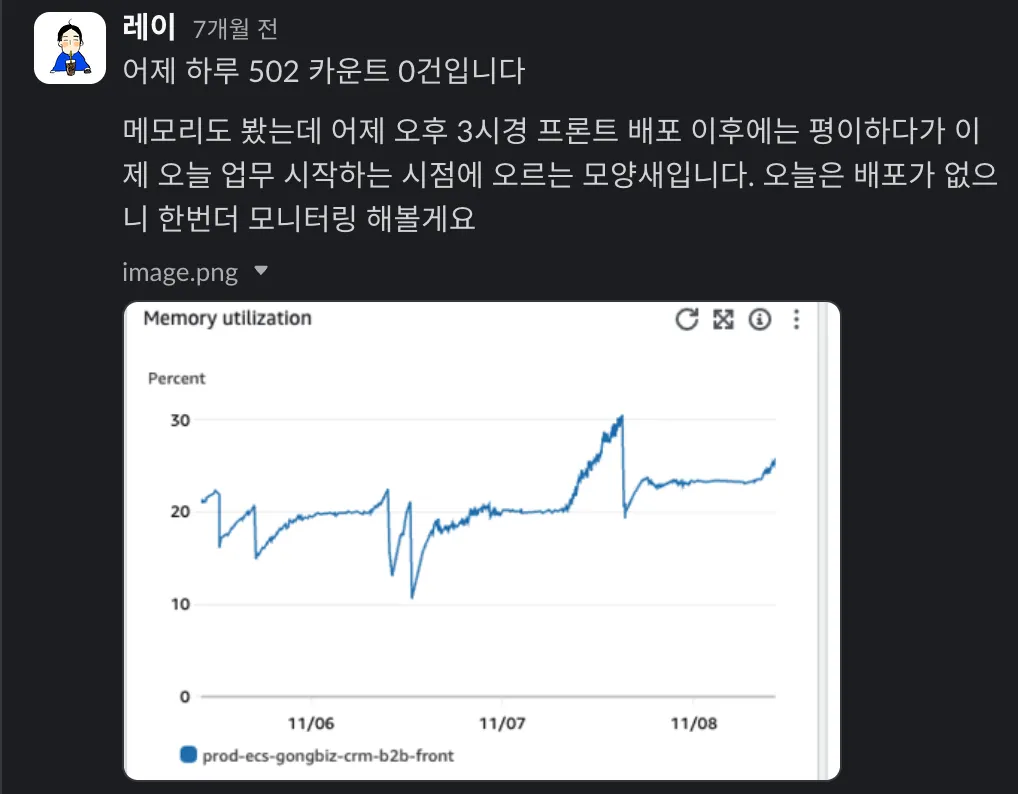
아쉽게도 장애 상황이 해소되지 않았습니다. 지속적으로 모니터링 하는 과정에서 502 에러가 계속 발생했습니다. 또 다른 장애로 프론트 애플리케이션의 메모리 부족 현상이 발생하였고, 이에 따라 비정상적으로 요청이 많아지게 되었습니다.
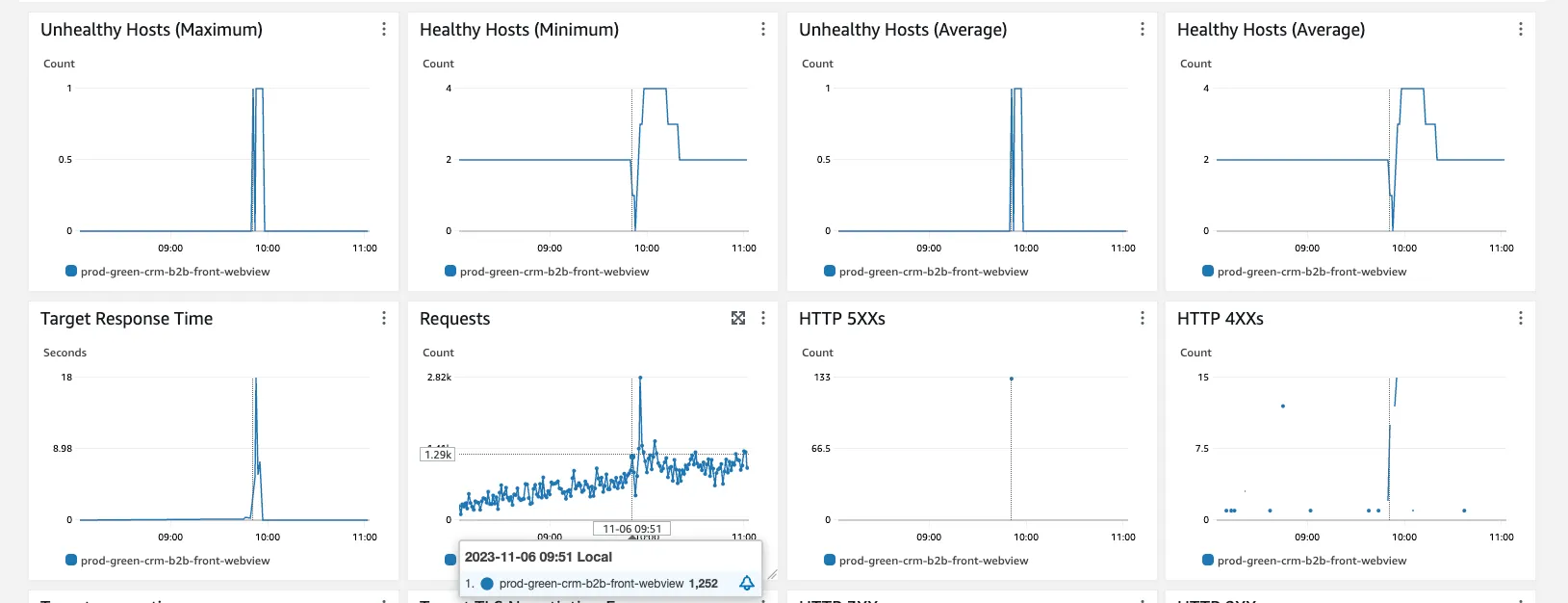
이번 상황은 메모리 부족 이슈가 있었으므로 메모리를 증설하였습니다. 인스턴스 메모리를 1GB에서 2GB로 증설했습니다. 앞선 상황도 스케일아웃된 인스턴스가 스케일인 되는 상황에서 발생하였는데요. 특별히 트래픽이 많아진 상황이 아닌데도 메모리 부족으로 인해 스케일아웃이 되는 상황이 발생했고, 이게 해소가 되면서 스케일인이 되어 다시 첫번째 장애가 반복되는 것 처럼 보였기 때문에 메모리 문제를 해결하여 방지하고자 했습니다.
2차 조치후 해결된 것 처럼 보였는데…
3차 조치
2차 조치로 인해 메모리 부족 현상이 발생하지는 않았습니다만, 아쉽게도 모니터링 하는데 계속 에러가 발생했습니다. 조치 다음 날엔 없었는데, 그 후에 발생하더라고요. 그래서 정확한 원인을 찾고자 계속 분석을 했는데요. Next.js 애플리케이션 로그에 다음과 같은 로그가 있었습니다.
could not build optimal types_hash, you should increase either types_hash_max_size: 1024 or types_hash_bucket_size: 64; ignoring types_hash_bucket_size
SQL
복사
이 에러는 Nginx가 MIME 타입을 빠르게 조회하기 위해 해시 테이블을 사용하는데, 이 테이블의 크기가 작을 경우 발생하는 에러였습니다. 최초 장애에 대한 근본적인 해결책인지는 모르겠지만, 뭐라도 대응하여 해결되길 바라는 마음에 Nginx 설정을 수정하여 해시 테이블의 값을 늘렸습니다.
4차 조치
3차 조치로는 바뀐 것이 없었고, 또 장애가 발생했습니다. 이전의 조치 내용들은 근본적인 원인을 제거하지 못 했습니다. 이번에는 진행하는 프로젝트를 모두 홀드하고 이 장애를 해결하고자 가용한 인원들 모두 원인을 분석하기로 했습니다.
장애가 발생했을 때 프론트 도메인으로 직접 접근하면 정상적으로 접근이 되었습니다. 반면 메인 도메인에서 프론트 페이지를 프록시를 타서 접근하면 장애가 발생했습니다.
즉, 프록시에서의 문제였는데요. 백엔드 JSP에서 로그인 후에 바로 메인 기능이 Next.js 프론트 페이지여서 마치 전체 기능이 동작 안되는 것 처럼 보였습니다. 특히 로그인을 이미 해놓은 상황에서는 바로 메인 기능으로 접근하기 때문에 인지가 잘 안되었던 것 같습니다.
백엔드로 접근 한 후에 프록시로 Next.js를 호출하는 구간에서 어떤 문제가 있는지 분석하기 시작했습니다. 이와 동시에 유지보수 계약을 맺었던 AWS 벤더사에 연락하여 장애 상황들을 설명하고 봐달라고 요청했습니다. 또 Nginx 프록시 서버 문제이니 Nginx 기술지원을 일회성으로 받기로 했습니다.
처음에는 벤더사에서도 자세한 원인을 파악 못 했는데, SA 인력에게 요청한 후에야 정확한 원인이 파악 되었습니다.
문제 원인은 다음과 같습니다.
1.
AWS ELB는 복수의 IP가 할당이 되며 트래픽 등에 의해 동적으로 IP가 늘어나거나 줄어들면서 IP변경이 일어납니다.
2.
Nginx Proxy에서 가지고 있는 DNS 캐시는 이전에 있던 ALB의 IP 였기 때문에 바뀐 ALB(IP)로 가지 못합니다.
[참고 레퍼런스]
•
AWS 로드밸런서는 DNS에 IP주소를 유동적으로 관리합니다.

There are several operations that can cause the IP addresses for a given ALB or CLB to change. When they do change, new IPs will be added to DNS and the old IPs will be removed. To use ALB and CLBs, we recommend clients to resolve the ELB DNS name and follow the best practices of honoring DNS TTLs (1 minute for all ELBs), retrying failed requests with exponential backoff and jitter, and refreshing DNS after a connection failure.
•
Nginx DNS 룩업을 위해 DNS record를 캐시하고 TTL을 무시합니다.

NGINX는 레코드의 TTL 값을 무시하고 다음에 다시 시작하거나 구성을 다시 로드할 때까지 DNS 레코드를 캐시합니다.
이후 이 현상을 재현하기 위해 운영이랑 똑같은 개발 환경에서 재현을 해봤습니다. 처음에 정상적으로 서비스를 이용한 후에, 프론트 서버의 Subnet을 변경하여 IP가 변경되도록 유도했습니다. 이후 시간이 지나면서 ALB의 private ip가 변경되었습니다. Nginx에서는 기존에 캐시하던 IP로 요청을 보내고, 목적지가 없어졌으므로 504 에러가 발생하는 상황을 재현하였습니다.
변경 전
crm-dev4-ssr.gongbiz.kr. 60 IN A 52.78.49.0
crm-dev4-ssr.gongbiz.kr. 60 IN A 43.200.134.242
Plain Text
복사
변경 후
crm-dev4-ssr.gongbiz.kr. 60 IN A 52.78.85.88
crm-dev4-ssr.gongbiz.kr. 60 IN A 52.78.49.0
Plain Text
복사
에러 로그 재현
•
변경 전 IP로 요청을 보냄
2023/12/21 15:44:07 [error] 22717#22717: *898 upstream timed out (110: Connection timed out) while connecting to upstream, client: 172.31.84.88, server: , request: "GET /book/calendar HTTP/1.1", upstream: "https://43.200.134.242:443/book/calendar", host: "crm-dev4.gongbiz.kr", referrer: "https://crm-dev4.gongbiz.kr/mypage/owner"
2023/12/21 15:44:07 [warn] 22717#22717: *898 upstream server temporarily disabled while connecting to upstream, client: 172.31.84.88, server: , request: "GET /book/calendar HTTP/1.1", upstream: "https://43.200.134.242:443/book/calendar", host: "crm-dev4.gongbiz.kr", referrer: "https://crm-dev4.gongbiz.kr/mypage/owner"
Plain Text
복사
1차 조치 때 모니터링에서 확인된 것 처럼 스케일 아웃된 상황에서 다시 트래픽 저하로 스케일 인이 될 때 문제가 발생하는 것 처럼 보였는데, 바로 이 문제 때문이었습니다. 그리고 신기하게도 주말 즈음에만 발생했는데, 주말 새벽에 트래픽이 줄어드는 상황에서 스케일인이 되면서 발생한 것 이었습니다.
이를 해결하기 위해 Nginx에서 DNS 캐시를 사용하지 않도록 하려고 했습니다. 이미 Nginx 기술지원을 요청했었던 상황이라 이를 위해 어떻게 하면 되는지 물어봤습니다. 여기서 아쉬운 점은 기술지원 측에서 관련 설정들에 대해 설명이 정확하지 않았습니다. 해당 설정은 Nginx 쿡북이라는 책에서 확인해보니 Nginx Plus(유료 구독 모델)을 사용해야만 적용 가능한 설정이었습니다. Nginx 기술지원은 사실상 의미가 없었어서 아쉬웠습니다.
장애 해결
장애 해결을 위해 세 가지를 고려했습니다.
1.
백엔드 AWS EB의 인스턴스 이미지를 Nginx Plus가 동작되는 것으로 변경
2.
프론트 앞단에 NLB를 추가하여 고정 IP를 만들기
3.
백엔드 AWS EB를 Apache 프록시 서버 사용 가능한 Tomcat Platform으로 다시 전환하기
이 중 첫번째는 Nginx Plus 유료 구독 모델을 사용해야 해서 패스했고, 두번재 방법은 MultiAZ 구성이 안돼 가용성이 저하되므로 패스했습니다. 최종적으로 세번째 방식을 적용하기로 했습니다.
다행히도 작년 10월에 Tomcat 9 Platform이 JDK 17을 지원하여 출시되었었습니다. 그래서 현재 적용된 JDK 17을 유지한채 인프라를 변경할 수 있었습니다.
작년 백엔드 인프라 개선 때 JDK 17로 버전 업그레이드 하는 것이 목표여서 Java Platform으로 전환 했었는데, Tomcat 9, JDK17 플랫폼이 조금만 더 일찍 나왔더라면 하는 아쉬움이 남네요.
AWS 인프라 변경
작년에 EB를 Java Platform/JDK 17로 변경했을 때 이 플랫폼은 Nginx 프록시 서버만 사용 가능해서 Nginx을 사용했었는데요. 이를 Apache를 사용하도록 변경하기로 했습니다. 왜냐하면 Apache 웹 서버에서는 무료로 DNS 캐시 비활성화를 지원하기 때문입니다.
다음 처럼 아파치 프록시 설정이 있는데, ttl과 disablereuse를 사용했습니다.
AS-IS
ProxyPassMatch ^/mobile-verification(.*)$ https://${CRM_FRONT_SERVER_DOMAIN}/mobile-verification$1
ProxyPassReverse /mobile-verification https://${CRM_FRONT_SERVER_DOMAIN}/mobile-verification
Plain Text
복사
TO-BE
ProxyPassMatch ^/mobile-verification(.*)$ https://${CRM_FRONT_SERVER_DOMAIN}/mobile-verification$1 ttl=60 disablereuse=On
ProxyPassReverse /mobile-verification https://${CRM_FRONT_SERVER_DOMAIN}/mobile-verification
Plain Text
복사
•
disablereuse=On 옵션을 통해 프록시된 백엔드(upstream) 서버를 재사용하지 않도록 설정하여 매 연결마다 새로운 연결을 생성하게 됩니다.
•
ttl=60 옵션을 통해 백엔드 서버와의 연결을 최대 60초 동안 유지하도록 합니다.
이 두 옵션을 통해 60초 동안은 재사용을 하되 60초 이 후에는 재사용을 하지 않고 새로운 연결을 생성하도록 합니다. 즉, 위의 장애 상황에서 프론트 ECS의 ALB가 스케일 인 될 때 죽은 IP로 요청하지 않고 새로운 연결로 동작하도록 최대한 타협을 한 설정입니다. 이후 모니터링 결과 502/504 에러가 발생하지 않았고 장애가 발생하지 않았습니다.

드디어 장애 해결합니다!!
오토스케일링 설정 조정
이번 프록시 이슈 장애는 해결 했지만, 운이 나쁘게도 새로운 백엔드 인프라 변경 후에 프론트 WebView 쪽에서 속도 저하 이슈가 발생했습니다. 트래픽이 점차 올라가는 시점에 스케일아웃이 늦게 되면서, 현재 인스턴스 수로는 트래픽이 부족해 스케일아웃이 완료될 때 까지 속도가 저하되는 이슈였습니다.
기존의 오토스케일링 설정은 CPU 사용률이 40%를 Threshold로 처리되고 있었는데요. 이는 기존 CPU 사용률 추세가 뷰티샵 원장님들의 주중 영업시간(오전 9시~오후 9시) 정도에 CPU 사용률이 올라갔다가 내려가는 사이클 상에서 최대치가 35 정도였기 때문에 40으로 맞췄습니다. 추가 트래픽이 많아질 경우 CPU 사용률이 40%가 넘어갈 때 스케일 아웃을 하는 목적이었죠.
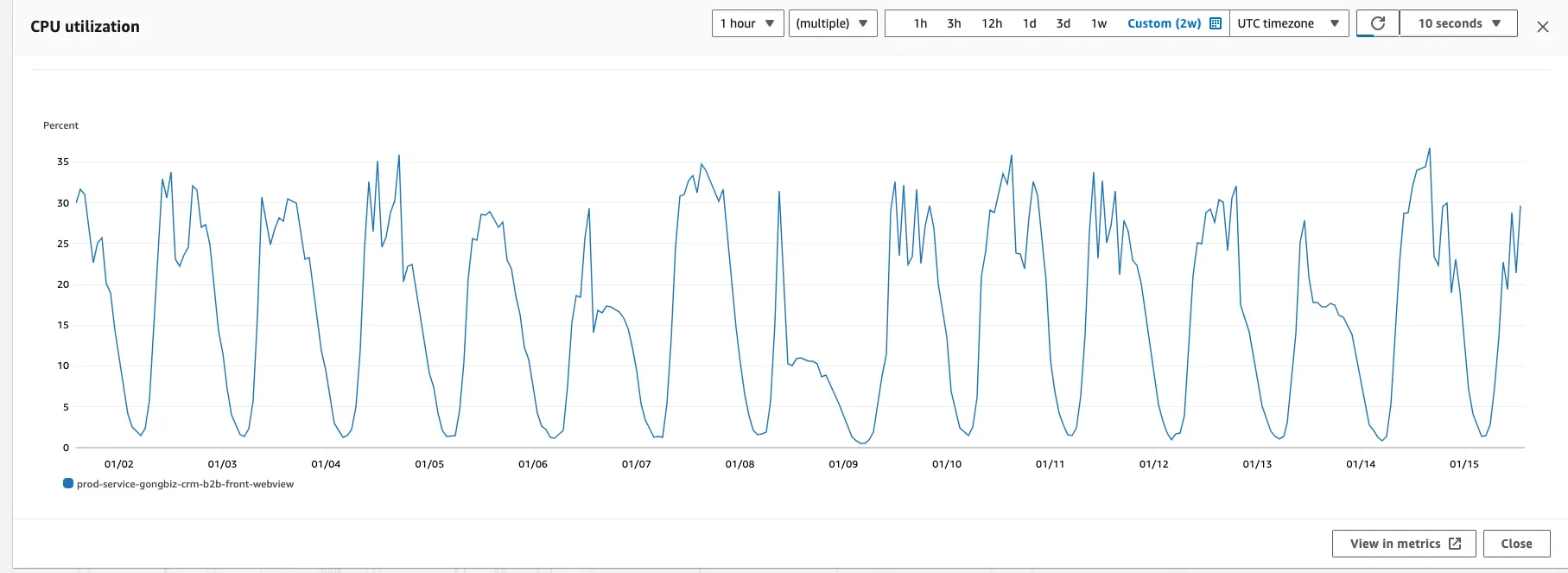
하지만 특정 시간대에 트래픽이 순간적으로 몰릴 때 스케일아웃이 되는 과정에서 속도가 저하되었습니다.
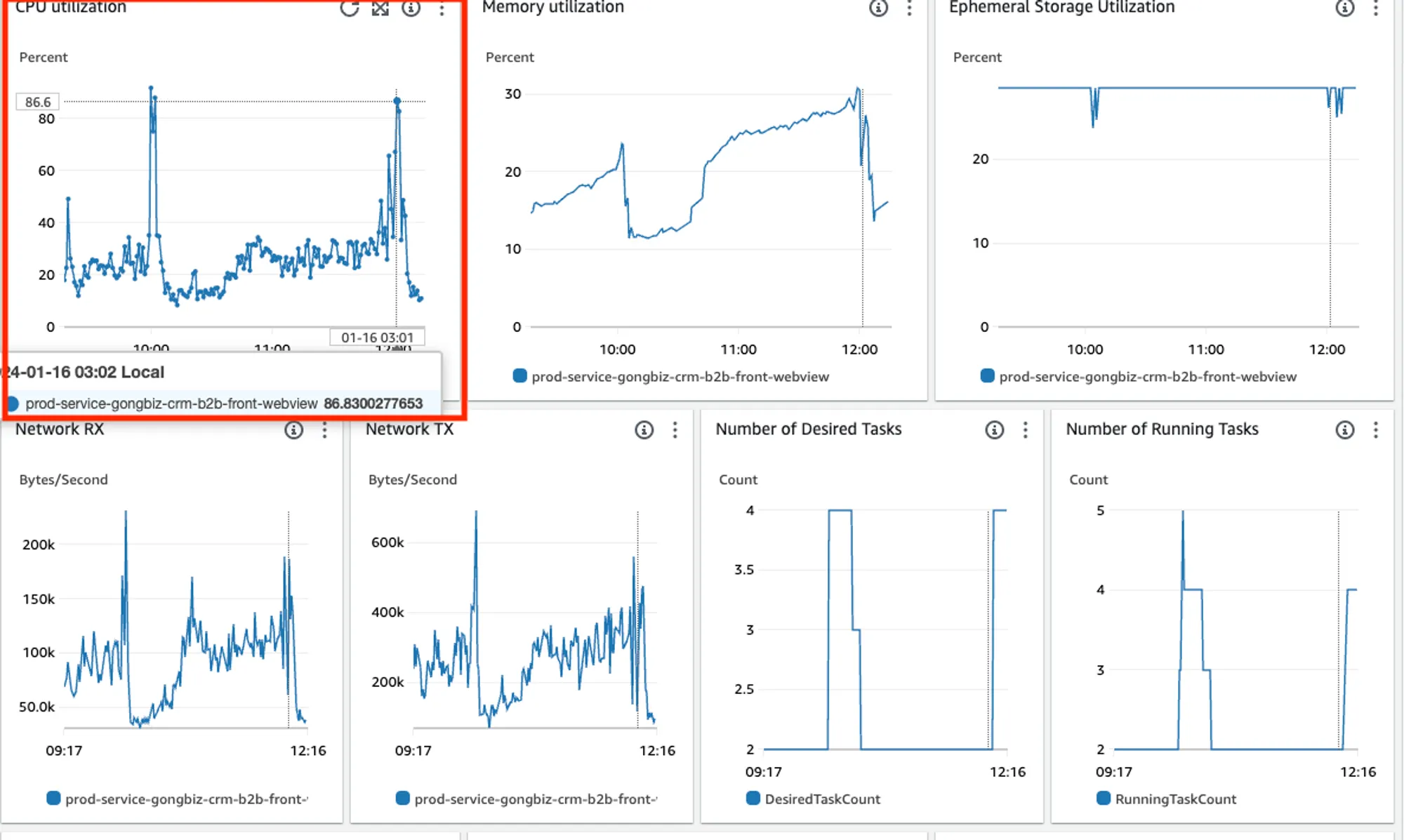
오토스케일링 기준을 CPU 사용률 15%로 하향 조정하고, 최소 인스턴스 수를 2개에서 3개로 늘렸습니다.
이유는 원장님들 영업 시작 전후의 CPU 사용률이 15% 정도였습니다. 즉, CPU 사용률이 15%이면 기본적으로 최소 3대가 동작하다가, 영업 시간대에는 사용률이 높아지면서 스케일 아웃 되어 충분한 인스턴스들로 트래픽을 받아주도록 설정한 것입니다.
결과
3개월에 걸쳐 여러 장애 이슈들의 근본 원인인 백엔드 → 프론트 프록시 이슈와 오토스케일링 이슈 등을 해결하였습니다. 이후 현재까지 장애 보고서를 작성할 일이 없어졌습니다. 가장 마지막 장애 보고서가 오토스케일링 조정 이슈였던 4개월 전이네요.
비록 초기에 근본적인 원인 파악이 안되어 오래걸렸지만, 지속적인 모니터링과 원인 분석을 통해 고객분들께 안정적인 서비스를 제공할 수 있게 되었습니다.
이후 후속 조치로 모니터링 지표들에 대해 알람을 설정하여 비슷한 상황 발생했을 때 장애 모니터링 채널에 알람을 확인할 수 있도록 했습니다.
회고
하인리히의 법칙이라고 아시나요? 한 번의 큰 재해가 발생하기 전 그와 관련된 작은 사고와 징후들이 일어난다는 법칙입니다. 평소에 5xx 에러에 대한 알림 모니터링도 잘 안되어 있었어서 사전에 장애를 발견하지 못 했습니다. 또, 4차례나 겪은 장애 상황에서 조금 더 철저하게 원인을 분석하고 빠르게 해결했었으면 좋았을 것 같다는 아쉬움이 남습니다. 분명 근본적인 해결이 아니었을 텐데, 당시에는 이것이 원인이었고 이렇게 조치했으면 충분하다는 마음이 있었던 것 같습니다.
또, AWS 벤더사의 지원을 적극적으로 받았으면 좀 더 빨리 원인을 파악했었을 텐데, 마지막에 가서야 문의를 한 것도 아쉬웠습니다.
인프라는 하면 할수록 신경 써야 할 것이 많은 것 같습니다. 단순히 배포시스템 변경, 인프라 구성 변경 뿐만 아니라 이에 대한 영향도와 미처 알 수 없는 예외 상황을 방지하기 위한 모니터링 등까지 신경 써서 구성이 필요하다는 것을 깨달았습니다. 마치 요리의 끝은 설거지라는 말 처럼요.
마치며
프로젝트를 개발하는데 바빠 4개월이 지나서야 글을 쓰게 되었습니다. 기억을 더듬고, 장애보고서와 슬랙 채널의 히스토리, 메일 히스토리들을 다시 보면서 글을 쓰게 되니 또 새롭게 보이는 것들도 많았습니다. 당시에는 빨리 장애를 해결하고 다시 프로젝트 업무를 하려는 마음 때문에 회고를 제대로 못 했는데요. 이번 기회에 당시 상황들을 돌이켜 보며 아쉬운 점들, 개선할 점들을 짚어보며 발전할 수 있는 기회가 된 것 같습니다.
고객들에게 좋은 가치를 빠르게 전달하는 것도 중요하지만, 안정적인 서비스를 지속적으로 제공하는 것 또한 중요한 일인 것 같아요. 그래서 서비스 운영이라는 것이 참 어려운 것 같습니다. 그래도 앞으로도 좋은 서비스를 제공하기 위해 더욱 정진하겠습니다. 감사합니다.